SpecMerger
An introduction to SpecMerger, a tree-diffing tool designed to facilitate mechanized specification audits.
Specifications (such as RFCs, programming language standards) are typically written in natural language. To formally verify an implementation of such a spec, we need two things: a mechanization of the spec (in a theorem prover like Coq, Lean, Dafny, …), and a proof of correctness relating the implementation to the mechanized spec.
The correctness of the proof is guaranteed by the theorem prover. But who checks the correctness of the mechanization? The original spec is in natural language, so the best we can do is an audit. To make these audits easier, some specs are written in a “literate” style, with comments from the spec interleaved throughout the mechanization. This helps a lot, but… who checks the comments? In this post, I present SpecMerger, a tool that checks that literate comments match the spec they came from.
Here is an example from the Warblre JavaScript regex spec [Warblre+ICFP24]:
(** >> AtomEscape :: CharacterEscape <<*)
| AtomEsc (ACharacterEsc ce) =>
(*>> 1. Let cv be the CharacterValue of CharacterEscape. <<*)
let! cv =<< characterValue ce in
(*>> 2. Let ch be the character whose character value is cv. <<*)
let ch := Character.from_numeric_value cv in
(*>> 3. Let A be a one-element CharSet containing the character ch. <<*)
let a := CharSet.singleton ch in
(*>> 4. Return CharacterSetMatcher(rer, A, false, direction). <<*)
characterSetMatcher rer a false directionYou can see how every line of the original specification appears in the mechanization as a special comment. That makes it easy to audit the mechanization, by checking that each line matches its attached comment. But do the comments match the original specification?

The corresponding fragment in the ECMA Specification
That's where my tool comes in! It automatically checks the comments for differences with the specification.
If you want to directly see an example of what is achievable in this tool, you can head to the test example of the repository which compares two JSON documents.
If you wish to look for a bigger project where this tool was used, you can have a look at Warblre in the specification_check folder.
This tool is in the style of Duvet, which does similar checks for RFCs: we wanted to have something similar for our JavaScript regex mechanization, and we thought it would be fun to build it as a generic tree differ.
So, how does it work?
String diffs?
A first idea would be to extract the comments from the mechanization, and the pseudocode from the specification and then do a string diff on it. This way we would directly see any difference. However, this method has some flaws: For example there might be some elements for which ordering might not be important. Think for example about bullet points: Even if their order differs between the spec and mechanization, it should not matter, right?
Another problem we encounter is when we have some structure which we know is different from the spec but that it should not report any error. To solve this we could add some special tags that ignore certain parts, which gives us more control about the error reporting.
How SpecMerger works
The way that someone would compare two different documents and report their differences would probably look like this:
First they would need to create two different parsers to transform the 2 documents into a custom format, then compare the fields of the two parsed results and finally report the diffs in a nice HTML report.
This is a lot of effort. We can, however, notice one thing:
If the structure of the custom format (which we will call tree from now on) is generic enough, the comparison and HTML rendering are always the same!
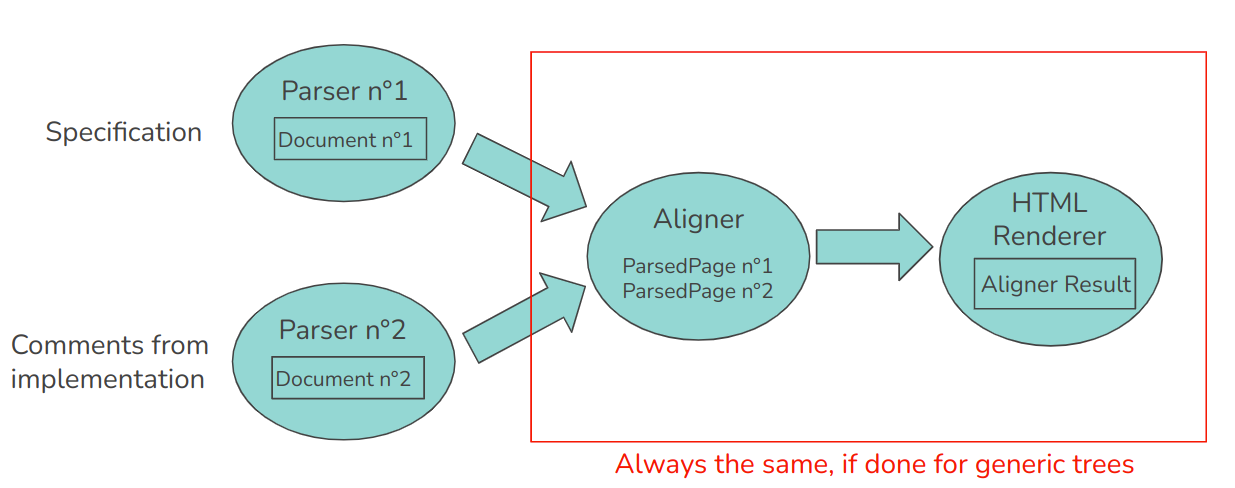
This is what the tool does! So the only thing that remains is to write a parser from both of your two documents into the custom tree format of SpecMerger.
The parser needs to transform the document into a tree where nodes (called Content) are already implemented to be able to be compared.
Different types of content
The Aligner will then take the two Content trees generated by the parser and try to merge them into a single Content tree.
There are many different types of nodes called Content implemented in the project, here they are:
String, a wrapper for a str valueDictionary, a map of str (and notString!) ->ContentOrderedDictionary, aDictionarywith ordering on its keysOrderedSeq, a List ofContentBag, a Set ofContentWildCard, an element which matches basically everything
Two special contents also exist called Misalignment and PartialAlignment but they should NEVER be included in the parser. These two Content exist because
the aligner needs to add them whenever there is a problem with the merge of the two trees. For example, if two elements that are being compared don't have the same type (well not exactly but it will be explained later),
this will add a Misalignment node with the left and right Content.
To give an example, if we look at the code that was shown on the top, the case AtomEscape :: CharacterEscape could be stored as an entry into a bigger Dictionary and its value
would be an OrderedDictionary with every line being an entry in it.
Comparing and merging trees
Let's go through an example to show how the tool would work:
Let's imagine that we have the following invented specification format:
# 22.13
Descrip.
- Important
- Please
- Keep
1. Let y=x²
2. Return x
@DATE: 12.08And now let's imagine that the code mechanizing it looks like this
// SECTION 22.13
// 1. Let x=2y
let x = 2*y
// \WILDCARD\
// @DATTE: 12.08Now suppose that we have a parser for both of these formats, this is what the trees would look like:
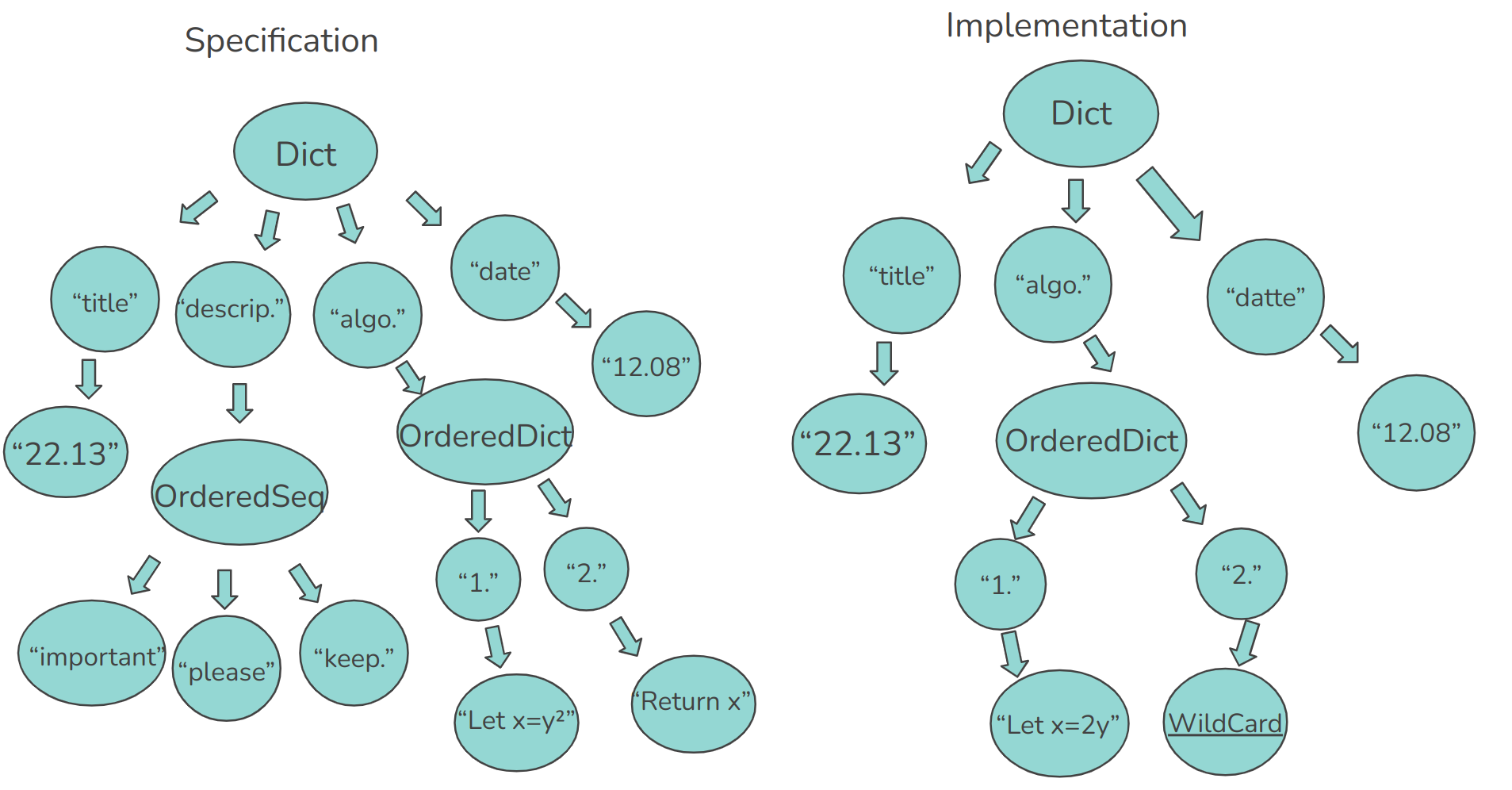
Can you spot the differences?
...
...
...
...
...
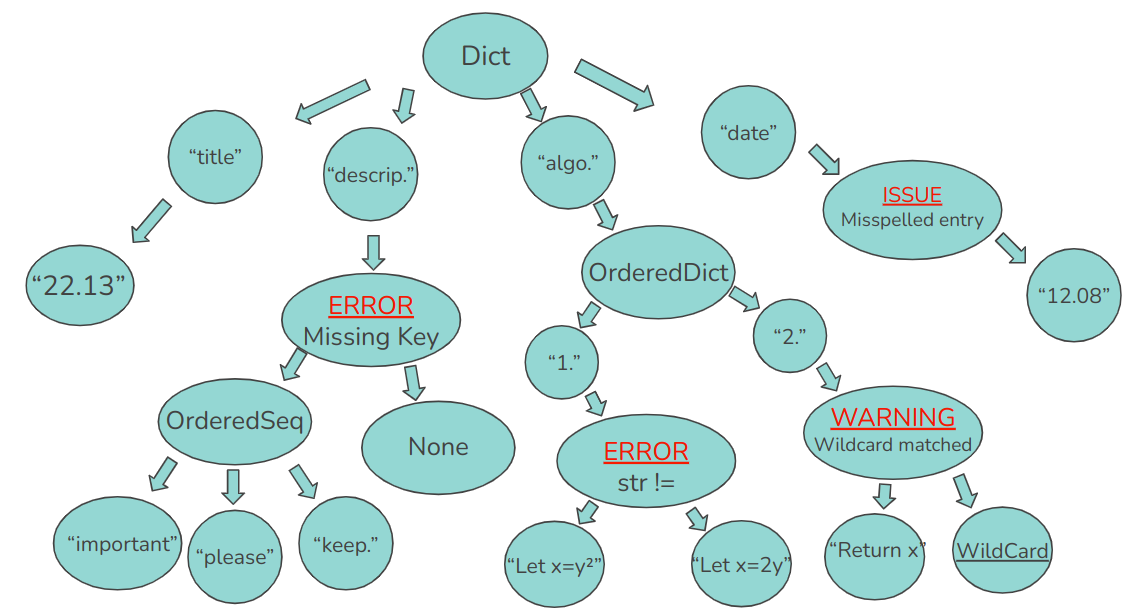
Here they are:
The "descrip." field is missing in the mechanization,
there is a typo in the "date",
the first instruction is different and
there is a wildcard in the 2nd instruction.
The Aligner would then produce the following tree:
How the comparison works
The Aligner class has a map that assigns to a pair of types (subtypes of Content) a comparison function (of type Content, Content -> Content).
This creates a very flexible pattern if you want to add a new comparison function between two type, or rewrite one of the already existing comparison functions.
To do so, you need to pass a prefilled dictionary in the constructor of Aligner.
from spec_merger.content_classes.dictionary import Dictionary
from spec_merger.content_classes.string import String
from spec_merger.content_classes.misalignment import Misalignment
from spec_merger.aligner_utils import ReportErrorType
from spec_merger.aligner import Aligner
fn_map = {(Dictionary, String): lambda dic,str: Misalignment((dic.position,str.position),dic,str,ReportErrorType.MISMATCHED_TYPES)}
aligner = Aligner(fn_map)
# Now aligner will call this specific function whenever it is comparing a Dictionary and a StringThis also makes it very easy to create a new subtype of Content: you just need to create the class and add the comparison functions!
Conclusion
SpecMerger has helped us increase our confidence in the Warblre specification: in particular, we found one place with an incorrect comment (thankfully, the Coq code was correct!). SpecMerger is now integrated in Warblre's CI, so such mistakes will never make it back into the repo!
SpecMerger is intended to be generic enough to be usable with other specs (not just Warblre), other mechanization languages (not just Coq), and other specification formats (not just HTML). Try it on your own mechanized specs and let us know what you think!
My work was funded jointly the Summer in the Lab program at EPFL and my host lab. I was very happy to do this project and I want to thank all the SYSTEMF team for having welcomed me in their lab!