Adding linear-time lookbehinds to RE2
An annotated guide to adding captureless lookbehinds to the RE2 linear-time regex engine.
Modern regexes are fiendishly complex: beyond traditional features like alternations and loops, they include complex constructs such as backreferences, possessive groups, recursion, conditionals, or bounded (and sometimes even unbounded!) lookarounds.
Surprisingly, the complexity characteristics of these modern regex features are not fully known. Take lookarounds, for example: until recently, if you wanted a regex flavor that supported lookarounds, you had to use a backtracking-based algorithm.
These backtracking engines have worst-case exponential complexity, and not just for backreferences — we're talking about engines that do this:
> "a".repeat(25).match(/(a*)*b/) // 350 milliseconds
> "a".repeat(30).match(/(a*)*b/) // 3.6 seconds
> "a".repeat(35).match(/(a*)*b/) // 37 secondsIn 2023, members of the lab showed that it's possible to match lookarounds in linear time [RegElk+PLDI24]. This was a bit of a surprise: it means that lookarounds are fundamentally safe, and that you don't need backtracking to match them. To demonstrate the practicality of this approach, the original paper had two implementations: a reference one in OCaml, and a fast one built on top of the V8 JavaScript engine (the one of Chrome and Node.js — if you have one of those, you already have our code!).
Here, we provide a third implementation: we show that RE2, a popular linear-time regex engine, can straightforwardly be extended to support lookbehinds in linear time [1].
Matching captureless lookbehinds in linear time
Let's start with a quick recap of the algorithm. Start with traditional NFA simulation, and add the following:
Create an empty table with one slot per lookbehind. That table will keep track, for each lookbehind, of the last position in the input string where that lookbehind matched. For example, in the string abbaba, the lookbehind (?<=ab) matches after the first and the third bs.
Compile each of the lookbehinds to a separate automaton, replacing each final state (an Accept instruction) with a new WriteLB instruction that writes the current string position to the table (and then continues running).
Compile the main regex, replacing each lookbehind with a CheckLB instruction that checks the table defined above.
Run all automata in lockstep, giving precedence to most deeply nested lookbehinds (WriteLB instructions need to be executed before CheckLBs).
Here is what the construction looks like:
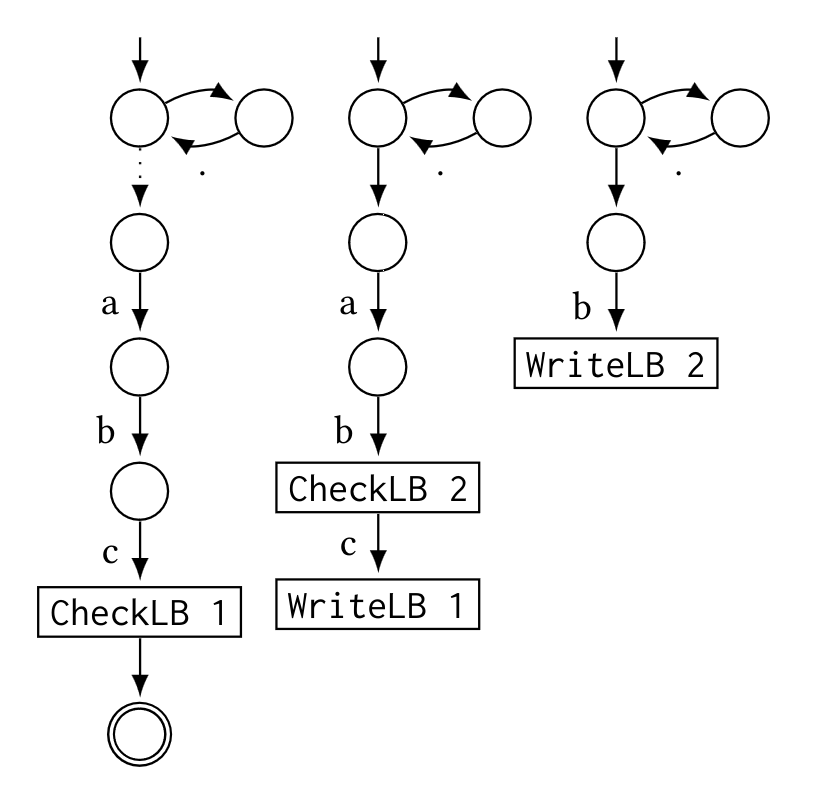
Main and lookbehind automata for the regex abc(?<=ab(?<=b)c).
RE2
RE2 is a C++ library that provides a fast, safe, thread-friendly alternative to backtracking regular expression engines. It is used by Google in various projects, such as Google Sheets, and in Open Source projects such as Pytorch and Prometheus. RE2 is based on a hybrid approach, mixing different types of linear algorithms (NFA simulation, lazy DFAs, etc.).
RE2's architecture
RE2 provides two main entry points: RE2::FullMatch(<string>, <regex>) and RE2::PartialMatch(<string>, <regex>). The first returns true if the regex matches the whole string, and the second one returns true if the regex matches a substring. When one of these functions is called, the following happens:
The regex in input is parsed and converted to an AST representation.
The AST is compiled to a program, representing the automaton corresponding to the regex.
One regex engine is chosen between DFA, OnePass, BitState, and NFA.
The engine runs taking in input the automaton and the string to be matched.
Here's the flowchart:
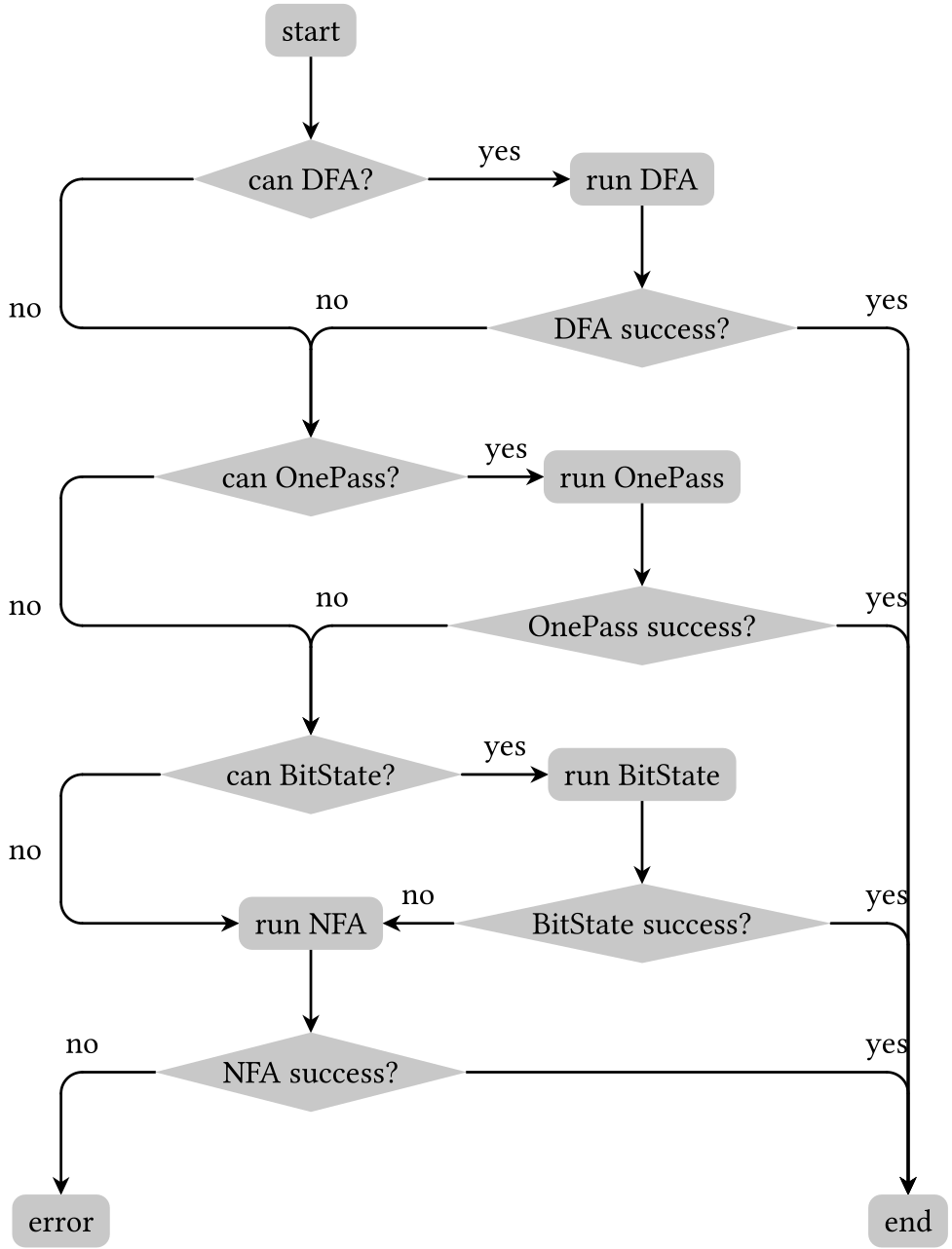
How Re2 decides which algorithm to use
Changes to support lookbehinds
Given RE2's structure, we need to change the following elements to implement captureless lookbehinds:
The parser should accept lookbehind syntax (?<=r) and add the appropriate tokens to the AST.
The compiler should generate one automaton for each lookbehind and include the WriteLB and CheckLB instructions.
The NFA should contain a table to keep track of lookbehind validity and it should run the automata in lockstep, giving precedence to automata representing the most nested lookbehinds.
The RE2 function choosing which engine to run should skip all engines and fall-back to the NFA if the regex contains a lookbehind (the only algorithm for which lookbehind support is implemented for now).
The tests should include captureless lookbehinds.
The following sections will focus on the changes to each one of these elements.
Changes to the parser
The code concerning the parser is included in the re2/parse.cc file.
First, we need to add an integer to keep track of the number of lookbehinds. We also add two pseudo-operators that exist only on the parse stack but will not be present in the final AST. This is done similarly as for capturing groups (kLeftParen).
@@ -181,6 +186,7 @@ private:
Regexp* stacktop_;
int ncap_; // number of capturing parens seen
int rune_max_; // maximum char value for this encoding
+ int nlb_; // number of lookbehinds seen@@ -189,12 +195,14 @@ private:
// Pseudo-operators - only on parse stack.
const RegexpOp kLeftParen = static_cast<RegexpOp>(kMaxRegexpOp+1);
const RegexpOp kVerticalBar = static_cast<RegexpOp>(kMaxRegexpOp+2);
+const RegexpOp kPosLookBehind = static_cast<RegexpOp>(kMaxRegexpOp+3);
+const RegexpOp kNegLookBehind = static_cast<RegexpOp>(kMaxRegexpOp+4);
Regexp::ParseState::ParseState(ParseFlags flags,
absl::string_view whole_regexp,
RegexpStatus* status)
: flags_(flags), whole_regexp_(whole_regexp),
- status_(status), stacktop_(NULL), ncap_(0) {
+ status_(status), stacktop_(NULL), ncap_(0), nlb_(0) {Then we need to handle when the lookbehind syntax is encountered in the regex string:
@@ -121,6 +121,11 @@ class Regexp::ParseState {
bool DoLeftParen(absl::string_view name);
bool DoLeftParenNoCapture();
+ // Processes a lookbehind in the input.
+ // Pushes a marker onto the stack.
+ bool DoPosLookBehind();
+ bool DoNegLookBehind();@@ -645,6 +653,18 @@ bool Regexp::ParseState::DoLeftParenNoCapture() {
return PushRegexp(re);
}
+bool Regexp::ParseState::DoPosLookBehind() {
+ Regexp* re = new Regexp(kLeftParen, flags_);
+ re->lb_ = ++nlb_;
+ return PushRegexp(re);
+}
+
+bool Regexp::ParseState::DoNegLookBehind() {
+ Regexp* re = new Regexp(kLeftParen, flags_);
+ re->lb_ = -(++nlb_);
+ return PushRegexp(re);
+}@@ -2307,6 +2344,19 @@ Regexp* Regexp::Parse(absl::string_view s, ParseFlags global_flags,
}
case '(':
+ if (t.size() > 4 && t[1] == '?' && t[2] == '<' && (t[3] == '=' || t[3] == '!')) {
+ if (t[3] == '=') {
+ if (!ps.DoPosLookBehind()) {
+ return NULL;
+ }
+ } else {
+ if (!ps.DoNegLookBehind()) {
+ return NULL;
+ }
+ }
+ t.remove_prefix(4);
+ break;
+ }Finally, when a right parenthesis is found closing the lookbehind, rewrite the pseudo-operator with the lookbehind token and parse the regex inside the lookbehind as a sub-expression:
@@ -720,6 +740,23 @@ bool Regexp::ParseState::DoRightParen() {
Regexp* re = r2;
flags_ = re->parse_flags();
+ // Handle lookbehinds.
+ if (re->lb_ != 0) {
+ // Rewrite LeftParen as lookbehind if needed.
+ if (re->lb_ > 0) {
+ re->op_ = kRegexpPLB;
+ re->AllocSub(1);
+ re->sub()[0] = FinishRegexp(r1);
+ re->simple_ = re->ComputeSimple();
+ } else {
+ re->op_ = kRegexpNLB;
+ re->AllocSub(1);
+ re->sub()[0] = FinishRegexp(r1);
+ re->simple_ = re->ComputeSimple();
+ }
+ return PushRegexp(re);
+ }The above are all the changes needed to implement captureless lookbehinds in the parser. For example, for the regex abc(?<=ab(?<=b)c) the parser will return the following tokens: cat{str{abc}plb{cat{str{ab}plb{lit{b}}lit{c}}}}, where plb denotes a positive lookbehind.
Changes to the compiler
The code concerning the compiler is included in files re2/compile.cc, re2/prog.h, and re2/prog.cc. The compiler takes the AST constructed by the parser and it builds the corresponding automaton. Our changes here focus on handling the kRegexpPLB and kRegexNLB tokens added in the parser:
@@ -953,6 +976,11 @@ Frag Compiler::PostVisit(Regexp* re, Frag, Frag, Frag* child_frags,
return EndRange();
}
+ case kRegexpPLB:
+ return LookBehind(child_frags[0], re->lb());
+ case kRegexpNLB:
+ return LookBehind(child_frags[0], re->lb());We then add two new instructions: LBCheck and LBWrite:
@@ -74,6 +82,8 @@ class Prog {
void InitAlt(uint32_t out, uint32_t out1);
void InitByteRange(int lo, int hi, int foldcase, uint32_t out);
void InitCapture(int cap, uint32_t out);
+ void InitLBWrite(int lb, uint32_t out);
+ void InitLBCheck(int lb, uint32_t out, uint32_t out1);
void InitEmptyWidth(EmptyOp empty, uint32_t out);
void InitMatch(int id);
void InitNop(uint32_t out);We need to add a LookBehind function that takes a fragment a (the regex inside the lookbehind) and returns a fragment containing a LBCheck instruction and a fragment containing the lookbehind regex with a .* at the beginning and a LBWrite at the end.
@@ -133,6 +133,9 @@ class Compiler : public Regexp::Walker<Frag> {
// Given fragment a, returns (a) capturing as \n.
Frag Capture(Frag a, int n);
+ // Given fragment a, returns (?<=a) if lb>0 or (?<!a) otherwise.
+ Frag LookBehind(Frag a, int lb);@@ -435,6 +438,26 @@ Frag Compiler::Capture(Frag a, int n) {
return Frag(id, PatchList::Mk((id+1) << 1), a.nullable);
}
+// Given fragment a, returns a fragment for the lookbehind (?<=a).
+Frag Compiler::LookBehind(Frag a, int lb) {
+
+ int id = AllocInst(2);
+ if (id < 0)
+ return NoMatch();
+ // LBWrite instruction, for the end of the LB automaton.
+ inst_[id].InitLBWrite(lb, 0);
+
+ // The automaton used to check the lookbehind.
+ Frag lb_automaton = Cat(DotStar(), a);
+ // Add the LBWrite instruction at the end.
+ PatchList::Patch(inst_.data(), lb_automaton.end, id);
+
+ // LBCheck instruction, for the main automaton.
+ inst_[id+1].InitLBCheck(lb, lb_automaton.begin, 0);
+
+ return Frag (id+1, PatchList::Mk((id+1) << 1), false);
+}At the end of this, we get a compiled regex with two new instructions: kInstLBWrite and kInstLBCheck. We also need to add a vector lb_start to keep the index of the starting instruction for each lookbehind automaton. The following code is in re2/prog.cc:
@@ -60,6 +62,12 @@ class Prog {
Prog();
~Prog();
+ std::vector<int> lb_starts;
+ void lb_add_start(int pos) {
+ // add to the beginning of the list.
+ lb_starts.insert(lb_starts.begin(), pos);
+ }@@ -616,6 +638,9 @@ void Prog::Flatten() {
if (ip->opcode() != kInstAltMatch) // handled in EmitList()
ip->set_out(flatmap[ip->out()]);
inst_count_[ip->opcode()]++;
+ if (ip->opcode() == kInstLBCheck) {
+ lb_add_start(flatmap[ip->out1()]);
+ }For the regex abc(?<=ab(?<=b)c) the compiler will return the following set of instructions:
3. byte [61-61] 0 -> 4 4. byte [62-62] 0 -> 5 5. byte [63-63] 0 -> 6 6. lbcheck 1 -> 7 7. match! 0 8+ byte [61-61] 1 -> 10 9. byte [00-ff] 0 -> 8 10. byte [62-62] 0 -> 11 11. lbcheck 2 -> 12 12. byte [63-63] 0 -> 15 13+ byte [62-62] 1 -> 16 14. byte [00-ff] 0 -> 13 15. lbwrite 1 16. lbwrite 2
Notice that the following corresponds to the example above, it can be easier to visualize if we separate the instructions of the different automata:
3. byte [61-61] 0 -> 4 │ 8+ byte [61-61] 1 -> 10 │ 13+ byte [62-62] 1 -> 16
4. byte [62-62] 0 -> 5 │ 9. byte [00-ff] 0 -> 8 │ 14. byte [00-ff] 0 -> 13
5. byte [63-63] 0 -> 6 │ 10. byte [62-62] 0 -> 11 │ 16. lbwrite 2
6. lbcheck 1 -> 7 │ 11. lbcheck 2 -> 12 │
7. match! 0 │ 12. byte [63-63] 0 -> 15 │
│ 15. lbwrite 1 │
Changes to the NFA engine
The code concerning the NFA engine is included in re2/nfa.cc.
As mentioned in the previous sections, we need to add a lb_table to keep track of the last string position in which a lookbehind was valid:
@@ -51,6 +51,9 @@ class NFA {
NFA(Prog* prog);
~NFA();
+ // Stores the last matching index of each lookbehind.
+ std::vector<const char *> lb_table;@@ -133,6 +136,7 @@ class NFA {
NFA::NFA(Prog* prog) {
prog_ = prog;
+ lb_table = std::vector<const char*>(prog->lb_starts.size());
start_ = prog_->start();
ncapture_ = 0;
longest_ = false;Once the NFA engine is started, we need to add a thread for each lookbehind. Each thread will start executing from the instruction index given in lb_starts. We also need to disable PrefixAccel when we have lookbehinds, as this function can skip some characters at the start of the string to be matched, causing errors in some lookbehinds.
@@ -575,13 +601,23 @@ bool NFA::Search(absl::string_view text, absl::string_view context,
// Try to use prefix accel (e.g. memchr) to skip ahead.
// The search must be unanchored and there must be zero
// possible matches already.
- if (!anchored && runq->size() == 0 &&
+ if (!prog_->has_lookbehind() && !anchored && runq->size() == 0 &&
p < etext_ && prog_->can_prefix_accel()) {
p = reinterpret_cast<const char*>(prog_->PrefixAccel(p, etext_ - p));
if (p == NULL)
p = etext_;
}
+ // Start threads for all lookbehinds positions.
+ for (auto & i : prog_->lb_starts) {
+ Thread* t = AllocThread();
+ CopyCapture(t->capture, match_);
+ t->capture[0] = p;
+ AddToThreadq(runq, i, p < etext_ ? p[0] & 0xFF : -1, context, p,
+ t);
+ Decref(t);
+ }Finally, the engine should handle the kInstLBCheck and kInstLBWrite when they are encountered. p is a pointer to the current character in the string to be matched, we use it to uniquely identify the current position in the string. kInstLBWrite writes the current position on the lb_table and kInstLB checks if the lb_table contains the current string position.
@@ -255,6 +260,27 @@ void NFA::AddToThreadq(Threadq* q, int id0, int c, absl::string_view context,
a = {id+1, NULL};
goto Loop;
+ case kInstLBWrite:
+ lb_table[std::abs(ip->lb())] = p;
+ break;
+
+ case kInstLBCheck:
+ if (ip->lb() > 0) {
+ // Positive Lookbehind.
+ if (!(lb_table[ip->lb()] == &p[0])) {
+ break; // Lookbehind failed.
+ }
+ } else {
+ //Negative Lookbehind.
+ if (!(lb_table[-ip->lb()] != &p[0])) {
+ break; // Lookbehind failed.
+ }
+ }
+ // Lookbehind succeeded: continue.
+ a = {ip->out(), NULL};
+ goto Loop;Changes to the function choosing the engine to run
As seen above, we need to fall-back to the NFA in case we have lookbehinds in the regex. To do this we need to change the Match function in re2/re2.cc:
longest_match_ ? Prog::kLongestMatch : Prog::kFirstMatch;
bool can_one_pass = is_one_pass_ && ncap <= Prog::kMaxOnePassCapture;
- bool can_bit_state = prog_->CanBitState();
+ bool can_bit_state = prog_->CanBitState() && !prog_->has_lookbehind();
+ bool has_lookbehind = prog_->has_lookbehind();@@ -741,6 +742,10 @@ bool RE2::Match(absl::string_view text,
return false;
case UNANCHORED: {
+ if (has_lookbehind) {
+ skipped_test = true;
+ break;
+ }The changes above force RE2 to discard all other engines and run the NFA directly if the regex contains lookbehinds.
Testing
Code for testing RE2 is for the most part contained within the re2/testing directory. re2/testing/parse_test.cc includes tests related to parsing, while re2/testing/re2_test.cc tests whether given regex strings match target strings.
The following tests were added to check the output of the parser with captureless lookbehinds:
@@ -178,6 +178,12 @@ static Test tests[] = {
{ "abcde", "str{abcde}" },
{ "[Aa][Bb]cd", "cat{strfold{ab}str{cd}}" },
+ // Lookbehinds
+ { "ab(?<=cde)", "cat{str{ab}plb{str{cde}}}" },
+ { "ab(?<!cde)", "cat{str{ab}nlb{str{cde}}}" },
+ { "ab(?<=c(?<=d)e)", "cat{str{ab}plb{cat{lit{c}plb{lit{d}}lit{e}}}}" },
+ { "ab(?<=c(?<!d)e)", "cat{str{ab}plb{cat{lit{c}nlb{lit{d}}lit{e}}}}" },The following tests had to be removed, given that they check if an error is thrown when a lookbehind is present:
@@ -572,15 +578,6 @@ TEST(LookAround, ErrorArgs) {
EXPECT_EQ(status.code(), kRegexpBadPerlOp);
EXPECT_EQ(status.error_arg(), "(?!");
- re = Regexp::Parse("(?<=foo).*", Regexp::LikePerl, &status);
- EXPECT_TRUE(re == NULL);
- EXPECT_EQ(status.code(), kRegexpBadPerlOp);
- EXPECT_EQ(status.error_arg(), "(?<=");
-
- re = Regexp::Parse("(?<!foo).*", Regexp::LikePerl, &status);
- EXPECT_TRUE(re == NULL);
- EXPECT_EQ(status.code(), kRegexpBadPerlOp);
- EXPECT_EQ(status.error_arg(), "(?<!");We added tests for matching some example strings:
@@ -609,6 +609,26 @@ TEST(RE2, FullMatchWithNoArgs) {
ASSERT_FALSE(RE2::FullMatch("hello!", "h.*o")); // Must be anchored at end
}
+TEST(RE2, LookBehindTest) {
+ ASSERT_TRUE(RE2::FullMatch("hello there", ".*there(?<=hello.*)"));
+ ASSERT_TRUE(RE2::PartialMatch("hello there", "(?<= )there"));
+
+ // Positive Lookbehind Tests.
+ ASSERT_TRUE(RE2::FullMatch("hello there", ".*there(?<=hello.*)"));
+ ASSERT_TRUE(RE2::PartialMatch("hello there", "(?<= )there"));
+ ASSERT_TRUE(RE2::PartialMatch("12345", "(?<=123)45"));
+ ASSERT_TRUE(RE2::PartialMatch("abc123def", "(?<=abc)123"));
+ ASSERT_TRUE(RE2::PartialMatch("abc123def", "(?<=123)def"));
+ ASSERT_FALSE(RE2::PartialMatch("abc123def", "def(?<=def(?<!f))"));
+ ASSERT_TRUE(RE2::PartialMatch("word1 word2 word3", "word2(?<=word1.*)"));
+
+ // Negative Lookbehind Tests.
+ ASSERT_TRUE(RE2::PartialMatch("abc123def", "(?<!def)123"));
+ ASSERT_FALSE(RE2::PartialMatch("abc123def", "(?<!abc)123"));
+ ASSERT_TRUE(RE2::PartialMatch("hello there", "(?<!goodbye )there"));
+ ASSERT_FALSE(RE2::FullMatch("goodbye", "good(?<!d)bye"));
+}Finally, we also tested whether the engine runs with linear time complexity when using regexes with lookbehinds. This was done by measuring the time taken to run the regex b(?:a(?<=ba*))* on string baⁿ, where aⁿ denotes a string of length n containing only as. The resulting plot is shown below:
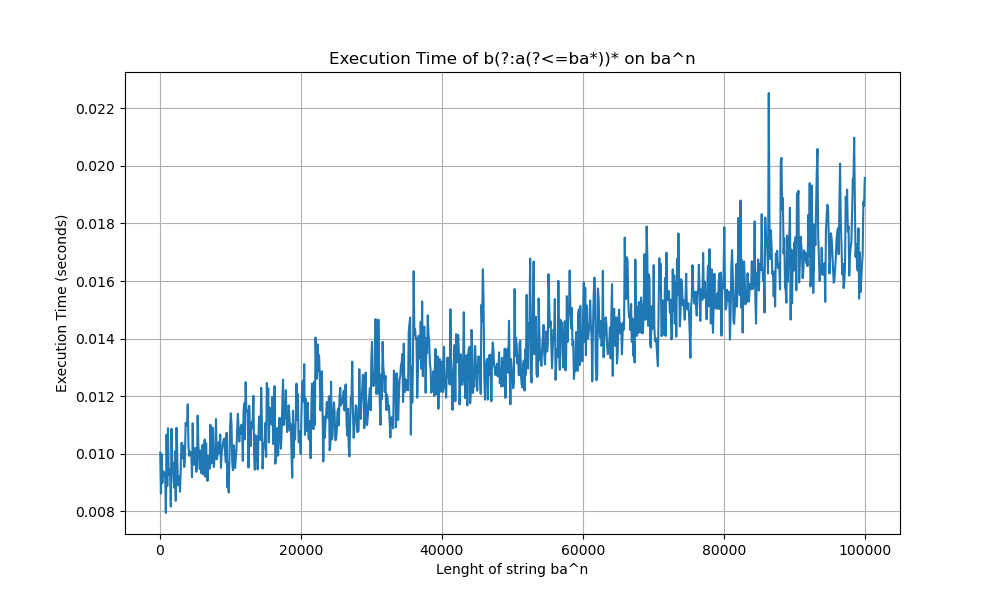
Execution time of b(?:a(?<=ba*))* on ba^n.
Conclusion
The overall patch is pretty short: just shy of 300 lines!
git diff --stat 6dcd83d
re2/compile.cc | 28 ++++++++++++++++++++++++++++
re2/mimics_pcre.cc | 2 ++
re2/nfa.cc | 38 +++++++++++++++++++++++++++++++++++++-
re2/onepass.cc | 5 +++++
re2/parse.cc | 52 +++++++++++++++++++++++++++++++++++++++++++++++++++-
re2/prefilter.cc | 2 ++
re2/prog.cc | 49 +++++++++++++++++++++++++++++++++++++++++++++++++
re2/prog.h | 37 +++++++++++++++++++++++++++++--------
re2/re2.cc | 11 ++++++++++-
re2/regexp.cc | 6 ++++++
re2/regexp.h | 12 +++++++++++-
re2/simplify.cc | 4 ++++
re2/testing/dump.cc | 4 ++++
re2/testing/parse_test.cc | 15 ++++++---------
re2/testing/re2_test.cc | 20 ++++++++++++++++++++
re2/tostring.cc | 11 +++++++++++
16 files changed, 275 insertions(+), 21 deletions(-)Our fork of RE2 containing all changes necessary to run regexes containing captureless lookbehinds can be found here.
Directions for future work could include:
Supporting captureless lookaheads, inspired by section 4.3 of Linear Matching of JavaScript Regular Expressions. This algorithm consists in running the NFA engine on a reversed regex string to compile a table of the positions in which the lookaheads hold. The NFA is then run again from left to right to determine if the regex matches the string in input.
While this implementation focuses on the NFA engine of RE2, it needs to be investigated whether it would be possible to implement lookbehinds in the DFA or other engines as well.